For the past few months, I've been working on reverie, an AI-powered journaling app that provides actionable insights and tracks mental well-being. One of the core features of the app is the "chat with journals" feature, that allows users to ask reverie about their journals, and it would answer in accordance with their journals, and also list the sources it's generating the answer from.
Objectives
Before designing the system, it's always good to list some objectives that the system is expected to achieve. I wanted reverie's chat to be
- answer questions based on user's journals
- understand dated queries (eg. what was I doing in second week of august?)
- filter journals on user emotions (eg. when was I angry about my food?)
- list the sources it's generating its answers from
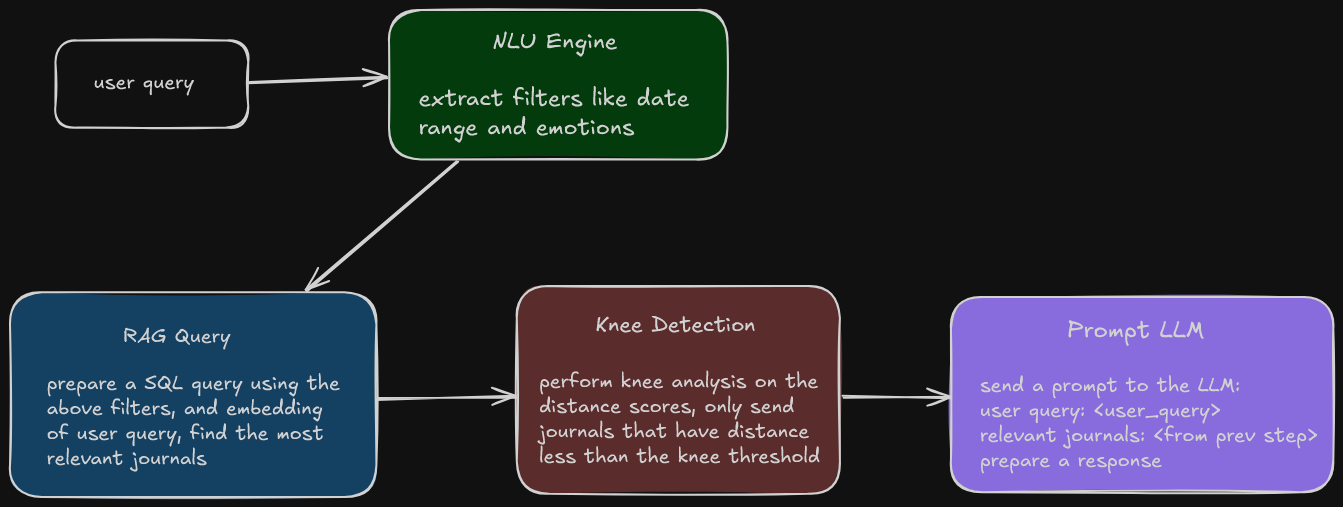
Keeping these objectives in mind, this was the high-level flowchart I designed (knee detection wasn't present in the initial draft, more about that later).
But before breaking down the pipeline, let's discuss some terminology we'll be using in the blog.
Embeddings
Embeddings are essentially just vectors (array of numbers) that capture the semantic meaning of its input. The input can be either text, images or audio. These embeddings are generated by embedding models, a kind of deep learning models which convert their input to numbers. An interesting thing about these embedding models is that the vectors generated by similar inputs, like car and automobile will be similar. This goes beyond the traditional keyword search, which will not consider the words car and automobile similar. Embeddings thus power semantic search, which will be used to find relevant journals.
Another notable thing about these vectors are that their dimensions vary on the embedding model used to generate them. I used the bge-m3 model due to its multi-linguality support, and its output dimensions are 1024.
Vector Operations
Now that we have vectors computed by the embedding models, how do we actually use them?
Remember the high school definition of vectors, they are objects which have both a magnitude and a direction. RAG involves finding out how similar those two vectors are. This is performed by computing the distance between them. The common vector distance operators provided by vector databases (more on them later) are:
- Euclidean distance (aka L2 distance)
Euclidean distance measures the straight line distance between two vectors.
As apparent from the equation, the resulting distance is highly influenced by the magnitude of vectors, so it's not particularly useful for text similarity. It has its belonging in clustering and KNN.
- Inner Product
This is essentially the negative dot product of two vectors.
It measures both the alignment and magnitude of the vectors.
- Cosine Distance
Cosine similarity is the cosine of angle between the two vectors.
Since cosine distance doesn't rely on magnitude but the alignment of the two vectors, it is highly suitable for semantic search.
It is interesting to note that the choice of distance function should also be influenced by the embedding model you're using. During their training, the embedding models optimize their losses using one of the distance functions mentioned above. For best results, the similarity metric used in vector search should match the objective the embedding model was trained with.
However, if the embedding model normalizes the embeddings using L2 normalization (magnitude of vector is unity), all distance algorithms become equivalent since they're only measuing the angular difference. Thus, the choice of distance function becomes irrelevant in such cases.
As always, read the docs of the embedding models and choose their recommended metric.
Vector Databases
Now that we have discussed embeddings and their operations, where do we store them?
Vector databases come into the play here. They provide means to efficiently store vectors and perform operations on them. Traditional databases suffer from the high dimensional nature of embeddings and were not built for handling this kind of workload. They also implenment ANN (Approximate Nearest Neighbor) search algorithms like HNSW and IVFFlat to quickly find through millions of vectors, instead of brute-forcing every pair of vector. Along with semantic search, they typically also support metadata-based filtering for structured search, which is also used in reverie.
Popular vector databases include pgvector, turbopuffer and pinecone.
RAG
Let's get back to the core objective of reverie's chat: we want the LLM to answer stuff asked about users's journals. But the LLMs can't possibly know about user's journals, they aren't included in the LLM's training data. It will hallucinate and generate incorrect answers.
RAG (Retrieval Augmented Generation) solves this problem by injecting correct context regarding the question into the prompt. We can't just dump the entirety of the journals into the prompt. With hundreds or thousands of them, it will burn through the tokens (🤑🤑) and might also slip through the context window of smaller models. It aims to accurately pick the relevant documents and add them to the prompt so the LLM answer is grounded. How do we find the relevant documents again? That's right, similarity search on vector embeddings.
Tech Stack
Since all of reverie's core backend services were written in Java using Spring Boot, I used the same technology for chat services, thanks to the awesome Spring AI library.
I need not mention that LLMs are used at some point in generating the answer. I used Gemini 2.5 Flash and Pro models since Google is very generous with their pricing.
For embedding models, I used the bge-m3 model because it's multilingual, available on Cloudflare Workers AI, and has a decent enough rank on the MTEB leaderboard.
Since I was already using PostgreSQL, I used pgvector with HNSW index and cosine similarity distance.
Pipeline
Let's start breaking down the pipeline now.
User Query
The user query is processed by converting it into an embedding so that it can be compared with other journal embeddings present in the vector database.
NLU Engine
The NLU (Natural Language Understanding) Engine is a lightweight LLM that is tasked with extracting structured information from the prompt. The information includes potential date ranges ("which movie did I watch in September" -> 01/09/25...30/09/25) and emotions ("when and why was I surprised"). I used the few-shot prompting technique to steer the model towards the kind of extraction behavior I wanted from the model. Few-shot prompting basically adds a few examples in the system prompt.
I used Spring AI's entity response method here, which automatically converts the desired output class into a JSON schema, and validates and parses the LLM response into the class we want.
Retriever
The output from the NLU engine is passed into the retriever along with the embedding of the user query. It dynamically generates a SQL query to fetch the user's journals that lie within the date range and has emotions (if detected by the NLU engine), and ranks them by their distance to the query embedding in ascending order.
The Criteria API provided by Hibernate was very useful for this task. But this is not the final step.
Knee Detection
Previously, the amount of journals was hardcapped to a limit. The same number of journals were always injected into the context, regardless of the query and their relevance to the query. I observed from the query patterns that answers to the queries often lie in a single journal, and seldom more than 5.
This was an optimization problem: the RAG retriever had to feed just enough journals to the LLM such that the LLM had enough context without spamming its history with irrelevant journals.
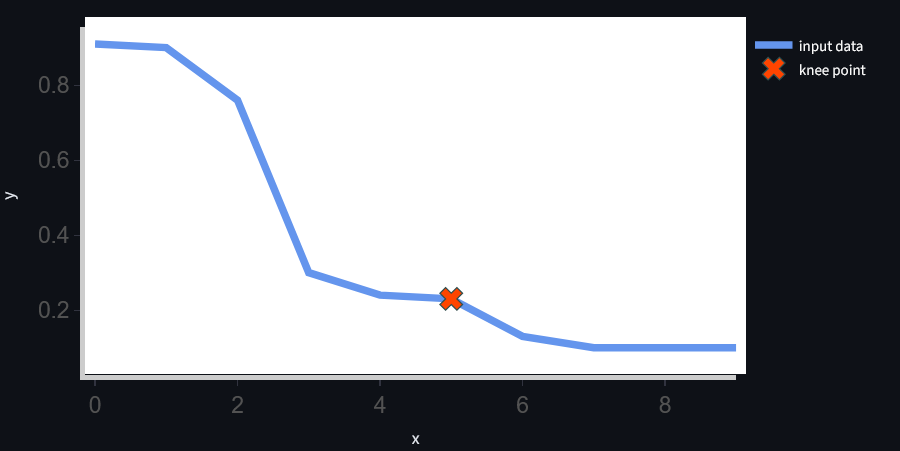
The Y axis represents the cosine similarity of the user query with each document (journal), and the X axis is just the index of journals. You can see how quickly the similarity falls, implying that only a select few journals are actually relevant to the query.
The problem then is how to find the knee point of the curve, the point of diminishing returns. A knee in computing is a critical point in a system beyond which the costs of adding more resources outweigh their benefits. I chose the Kneedle algorithm to find the knee point. Kneedle is an algorithm that finds the maximum curvature in a data set. I couldn't find a suitable Java implementation for my use case that supported all Kneedle input parameters, so I wrote my own library and open-sourced it, ported from the Python Kneed library.
Response Generation
The hard part is over. Once we have the relevant journals ready, we just inject them into the prompt and ask the LLM to answer the user query based on the provided journals. Again, Spring AI does the heavy lifting here.
Limitations
While the system is working, it's far from perfect. I have identified and wish to address these limitations with reverie in the future:
Monitoring
The first step in improving any system is to observe and monitor it. I want the system to monitor its responses, failures, latency, and user feedback in real-time as well as craft a golden dataset and test the system's performance on it with metrics like precision@k and recall@k on a periodic basis. This will help with judging whether any changes to the system are actually improving or degrading it.
Hybrid search
Another feature I'd like to add to this pipeline is hybrid search. While semantic search is great at understanding the general nuance of a document, keyword search brings precision. Combining both results in the best retrieval performance. TF-IDF and BM25 are widely-used keyword search algorithms. Both retrievers run together and their results are merged using RRF (Reciprocal Rank Fusion) or a weighted score method.